Telemetry ingestion
Adapters normalized vendor devices into one stream.
- MQTT, Modbus, and REST sources
- Offline buffering for low-signal regions
Client: Netline Group (Net-Line Pvt. Ltd.), Pakistan. They manage off-grid and hybrid solar sites in areas where connectivity is not consistent. When a site drops, minutes matter, but visibility was delayed.
The goal was clear. Give ops a real-time view, push alerts to the right people, and let partners run maintenance with proof, photos, and status updates. All without turning central ops into a call centre.
Real-time site health, faster fault handling, and partner-run maintenance. Enough structure to scale beyond 200 sites without growing the support team at the same rate.
Growth exposed the weak spots. Data was delayed, status checks were manual, and fault handling relied too much on phone calls. With more sites, the same issues happened more often.
We built a mobile-first remote ops platform that collects telemetry, triggers alerts, and tracks maintenance work end to end. Ops can see what is happening. Partners can acknowledge, fix, and close work with proof.
The system also had to survive low-signal regions. That meant offline-first mobile flows and safe delayed sync.
Adapters normalized vendor devices into one stream.
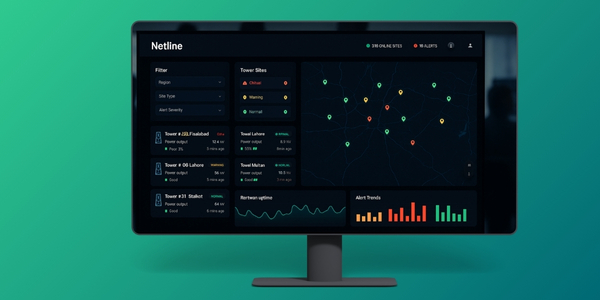
A live view that reduces status calls.
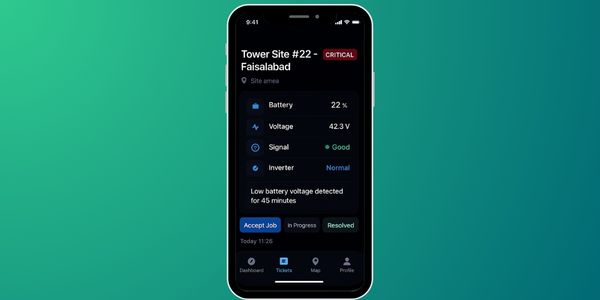
Actionable alerts with acknowledgment.
Field work stays structured even offline.
Find repeat issues and push proactive work.
The right view for ops, partners, and leadership.
We started with a controlled rollout across 50 sites. Different vendors, different firmware versions, and uneven connectivity were the reality. The platform had to normalize data and stay usable when signals dropped.
Early versions triggered too much noise. We tuned thresholds, added suppression logic, and tightened what counts as actionable. The goal was fewer alerts, but better ones.
The architecture was built around a simple idea. Telemetry is noisy. Workflows cannot be. We separated ingestion, alerting, and user workflows so each layer stays stable as volume grows.
This needed to ship without disrupting active operations. We ran discovery fast, built around real workflows, and used a pilot to tune alerts before scaling.
Real-time visibility plus structured partner workflows let them scale without turning ops into a constant escalation loop.